本格的に cross の bootstrap をやりたくなったのでswapforth と gforth の cross.fs を読む。
gforth は相当難しい上に、6052 とか 8086 とかの cross bootstrap?(コンパイル?) に失敗する。多分、メンテナンスされていない。swapforth は比較的簡単。といっても読むのにコツが必要だけどね。きっと1ヶ月後には忘れているのでここにまとめる。
ここにちょっと書いたけど、これより詳しく書く。ターゲットは j1a という 16bit の Forth。32bit 版の j1b というのもある。
tflash と tdp と tcp
基本的には allocate された領域 tflash にヘッダーとコードを書き込んでいく。そのためのポインタが tdp と tcp。ワードとして there(here の代わり)も使う。ターゲットに関連するワードは主に t で始まる。
今、j1a をターゲットにしているから全体のアドレス体系は 16bit 。なので、thereとすると、ターゲットの使っていないデータ領域の先頭のアドレスがスタックに積まれる。私の実行環境は 64bit。
target-wordlist
target-wordlist というのも定義している。これ、要はボキャブラリ。今の gforth なら vocabulary で実現可能なことを wordlist を使っている。開発したときは vocabulary がなかったのかな?
この辺はもうちょい今の gforth なら簡単になりそう。ちょっと試してみた。
回りくどくなったが、新たに作ったボキャブラリにだけ登録し、今は使えないワードというものを作っている。なので target-wordlist という名称になっているが正確に言えば wordlist-to-make-target だ。
ターゲットへのコード等の登録ではないことに注意されたい。
header
target-wordlist に登録されるワードで重要なものの一つがheaderだ。
バックスラッシュ(\)はコメントなので読み飛ばすとして(実\も再定義されている)本筋は twalign からその後。
twalign は16bitのアライメント調整。2バイトバウンダリにthere で取得できるアドレスを調整する。
there でまずアドレス積んで、link @ で link にセーブされていたアドレスを積み直して、tw, でそのアドレスをデータ領域に格納して tdp を更新。これで there は 16bit 分先に進む。アドレスに積まれた there はそのまま。つまり、今構築しようとしているヘッダーの先頭アドレス(つまりワードのアドレス)だ。そこで link ! とすると、link にそのワードのアドレスが書き込まれる。
複雑過ぎて何言っているかわからない。絵がないとだめだけど、今はそういう絵も書いてないので先に進む。
bl parse で header に後続するであろう名称を解析してスタックにアドレスとストリング(文字列)の長さを積む。このストリングは一体全体どこに格納されるのか?というと、特別な領域にアドホックに書かれる。その間に s" とかしちゃうと上書きされてしまう。
parse された後にはストリングの長さが入っているのでそれを dup して tc, これでヘッダーにストリングの長さが追加された。その後、まだ残っていたアドレスとサイズの情報をbounds で開始アドレスから終了アドレスに変換。do loop で回す。i でアドレスを取り出し c@ で 1バイト取り出す。これで順々にストリングをスタックへ取り出品がr,tc, でヘッダーにコピーする。
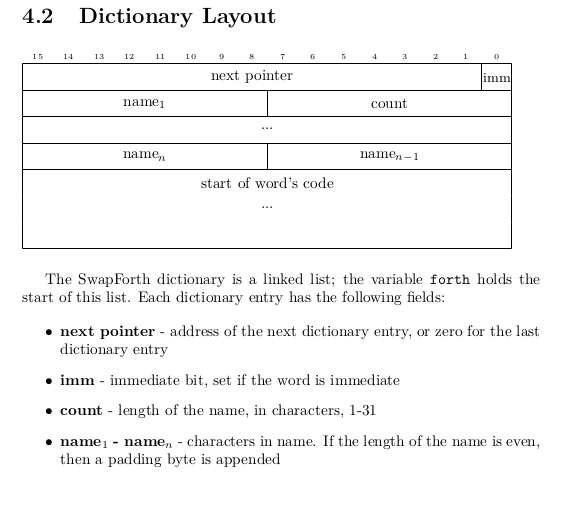
最後に twalign で境界を整える。これで j1a が要求するヘッダー部分が完成した。j1a のドキュメントから辞書のレイアウトを抜粋する。作者は TeX 使っているのね(ナ〜カ〜マ〜)。
header の使い方
header はクロス環境のデータ領域に、クロス環境用のヘッダーを書き込むだけだからそれだけではワードは完成しない。その後にワードで定義する処理を書かねばならず、それはには再定義された:と;を使う。凡例を示す。
さらに複雑なのが再定義された:はそのアドレスを後続する名称で Forth のワードリストに登録する。:が一般のコロンと違うのはヘッダーの外でも使え、header の定義で2回使うことも出来る。そのように使った場合、入れ子になるわけではない。つまり、ローカルなラベルと思っていい。ターゲット側では使われることないアドレスなので、Forth 側に登録されるようだ。
例えば uart-stat は nuc.fs 内では使うことが出来るが、一旦立ち上がった実機の swapforth 内からは使うことが出来ない。
コロン:
ヘッダーに後続するのはプログラム。これは:で定義する。通常のコロンは使えない。:: で :を再定義している。再定義と言っても、:: での定義なのでtarget-wordlist に登録されるだけでまだ使えない。
最初の5行は nuc.lst というファイルにアドレスのリスト(C で言えば nm で表示される関数マップ)を書き出しているところ。
there wordstart !の部分は登録対象となっているワードのコードの先頭アドレスをwordstart という変数に格納している。これは後に ;で使用される。
ここのポイントは create does> だ。この Forth のワードを使いこなせるとForth のプログラマぽい。複雑なのは create も実はターゲット用のワードで does> はそのまま。create の中で使われている create はオリジナルの Forth の create。
:で登録中に実行されるのは coderptr , の部分。,も再定義されておりターゲットのヘッダーに codeptr が登録される。
@ scall は後に:で他のワードを定義中に呼ばれたときに"実行"される。scall の定義を次に示す。アドレスをコールするプログラムを埋め込む。
セミコロン;
header を閉じるのは;だ。もうこの辺まで来ると、理解がコンガラって来て、「後処理するんでしょ」で済ませたくなる。
最初の if は workstart と tdp が同じだったら、つまりコードとしてのワードが全く書かれなかったらという条件判定。evaluate を実行している。evaluate は Forth のワードだが、exit は RET を埋め込むターゲット側の処理。
あとは shortcuts と tbranches の処理だが、何やってるんだろうね。then や repeat の処理のようだ。なんとなく、末尾呼び出しっぽいことやっている気がする。jump 命令に置き換え可能なら jump 命令を埋め込んでいる?ここはもう謎のままだ(力尽きた)。