浮動小数点数を使った積和演算を考える。過去に書いた FPGA マガジンの記事を参照しながら浮動小数点数の扱いを考えてみる。ターゲットは Sipeed の Tang-Nano-9K で Gowin の GW1NR が搭載されている。
記事のおさらい

記事では浮動小数点数の掛け算をするアクセラレータを FPGA で作り、これまた FPGA 内の RISC-V でそれを使う方法を考えた。
掛け算にしたのは足し算より掛け算のほうが簡単だから。積和演算ではない。
RISC-V で使う前に SW と LED で確かめた。ここが FPGA のいいところ?かな。プリミティブにまで降りていける。
その後、RISC-V の WB というバスにそのアクセラレータをくっつけた。
アクセラレータと言いつつ、何かを便利に速くする!!ということはないだろう。1つは一旦、RISC-V の外に情報を出し入れしているので、そのコストが高いということ。もう1つはコンパイラがないこと。
足し算の結果をLEDで見る
「RISC-V で使う前に SW と LED で確かめた」をもう少しおさらい。入力は固定値。sw0 を押すことで演算器の a と b のレジスタに浮動小数点数が"入る"。
ここでいうレジスタは CPU/GPU などでいうレジスタというよりRTL の世界のレジスタのイメージだ。半導体内の記憶域(DFF で構成されているだろう)に値を納める。
このイメージは個人的なものかもしれない。結局、レジスタという意味では同じだからね。

ここでは a と b という"レジスタ"にデータが入る(移動する)ということを明示的にしたいという思いがある。
いくつかのプログラムではこのデータの移動がボトルネックになって高速化できないということが起こる。
RISC-V から動かす
ほぼ、同じ演算器を今度は RISC-V から動かしてみる。

今度はデータが固定値ではない。C 言語で書いたプログラムから一旦今度は WB 経由のメモリ(これもレジスタといえばレジスタだ)に格納される。mem0 あるいは mem1 と図示されているところがそれ。
今プログラムを見てみると絵の通りちゃんと8個分の領域を確保している。2番目以降は現在使っていないが、なんとなく今後いっぱいアクセラレートするよ!という予告編的な絵になっているのだ。
データをメモリに入れた(移動させた)だけでは演算器は起動しない。WB 経由で開始の合図を送る。すると、データは a と b に移動し、計算結果が演算器内の c に蓄積される。
WB 経由で特定の領域を read すると c の値が"移動し"、ユーザのプログラム内にコピーされる。
絵を見ると IO の部分は結果をコピーしているように見えるが、ここにはメモリはない。だから絵では破線になっている。正確に書くと(う〜ん)、ここにはデータは蓄積されず、c の中のレジスタから直接ユーザメモリへとコピーする(移動する)ことになる。
蛇足ながら、WB 上には mem2 という領域も将来の拡張用として作っておいた。更に fadd という加算器も作ってある。
積和演算をやる準備は出来ている。
パイプラインはどうなっているのだ?
この乗算器、計算に時間がかかりそうな気がする。と思ったが、今、ソースを読んでみると、すごく、単純に書いた fmul で、1クロックで処理が終わってしまう。
そして、1クロック内に全部詰め込んでおり、DSP を使用していない割にはfmax は 140MHz を超えており、意外と速いなぁというのが個人的な感想だ。
1クロックで実行できちゃうとこの後の説明があまりしっくりこない気がする。そこで、以前作った fmul を持ち出すことにする。これはディジタル数値演算回路の実用設計を参考にパイプライン化したものでレイテンシーが 4 となった。
レイテンシーが4とはどういう意味だ?
レイテンシーが 4 になるということは、データを入力してから4 クロック後に結果を得ることができるということだ。実際に テストベンチを走らせてみた。
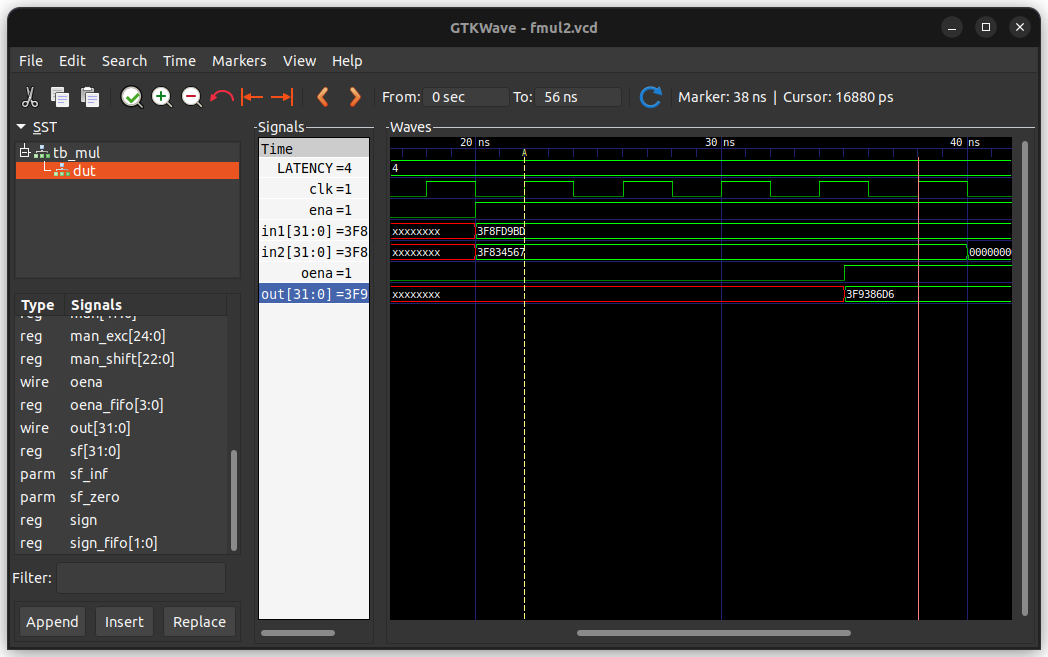
結果が分かりづらいが、入力に対して 4 クロック遅れて結果が出ている。(in1 を a, in2 を b, out を c に読み替えると今までの話と繋がりやすい)
イメージをつかみやすいようにアニメーション gif にもしてみた。縦が同じ時間に実行される処理だ。
a, b が入力で, c が出力だ。

To Be Continue...
PS
実は Xilinx 版、Intel 版(Altera になったのか、、、)とベンダーが用意している IP コアを使うバージョンもあるのだが、それは機会があれば公開することにしよう。
リンク集
lpha-z さんがいろいろ有益な情報を書いているので本文とは直接関係ないけど、リンクを貼っておこう(備忘録かな)