Vitis_Accel_Examplesを試すうちに内部構造を知る必要が出てきました。ここでは U50 の内部構造を見ていきます。
3部作になっています。
- 環境設定など(このページ)
- ソースを読む
- 内部構造の話(このページ)
HBM2(High Bandwidth Memory 2)
HBM2 は高帯域幅メモリでデバイスを作る上での技術の名称でもあります。
私にとって身近な DDR などは、DOS/V ショップで売っているモジュールで実際に手元にある Xilinx のボード(例えば ZCU-102 とか)にも搭載されていいます。
一方 HBM2 は Si Interposer の上のに DRAM を3次元的に!載せています。基板じゃなくてシリコン。日経 XTECH の Siインターポーザの説明によると「Siインターポーザは配線のみを作り込んだSiチップ」とのこと。
参考資料:広帯域と大容量にフォーカスした“第2世代”のHBM2メモリ
U50 は HBM2 を使っているということが1つ。そして、HBM はチャネルをもっているということが重要です。
SLR(Super Logic Region)
U50 はSSI(スタックド シリコン インターコネクト デバイス) デバイスです。「SSI デバイスでは、シリコン インターコネクトを介して複数のシリコン ダイが一緒に接続され、1 つのデバイスにパッケージされます。」(新規ターゲット プラットフォームへの移行から引用)とのこと。この SSI を構成するのが SLR で U50 は2つの SLR を持ちます。
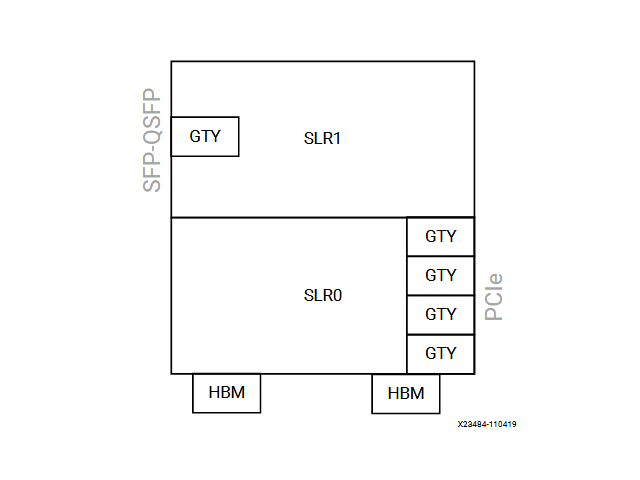
どこに影響してくるのか?
Vitis では cfg ファイルを使って、カーネルの配置であったり、メモリのアクセスをする為のインタフェースの指定をします。
例えばこんな感じ
DDR を積んでいる他の Alveo は HSB は指定せずに DDR を指定します。
通常はこのように 0:31 のチャネルどれ使ってもいいよと v++ に教えてやりv++ が都合よく解釈して最適化をこころみるでしょう。U50 の場合HBM がついているのは SLR0 だけなので、あまり選択の余地はないでしょう。
カーネルをどの SLR に配置するかも指定可能です。
SFP-SQFP を使用するのであれば SLR1 の指定をする必要があるでしょう。特に複数のカーネルを配置する場合は明示的にすることで効率をあげることが出来そうです。
複数のカーネル
複数のカーネルと言っても FPGA なので1つのビットストリームです。ap_start で起動するタイミングをもつ複数のモジュールが1つのビットストリームの中にあるという事のようです。ですから、複数のビットストリームに分散しているからと言って特段デメリットがあるわけではなく、むしろ、モジュールを分離できるのでうまく活用すべきです。
host/streaming_free_running_k2k
このサンプルは3つのカーネル(mem_read/increment/mem_write)があり非常に面白いサンプルになっています。ここではソースを掲げるだけで詳しく解説しませんが、中間の increment がAXI Stream になっているのが特徴です。
次のように cfg で各カーネルを接続することを明示します。
increment のインタフェースは次のように至って簡単です。ap_ctrl_none なのでだれもキックしません(ap_start がない)。したがって、HOST 側へのインタフェースも持ちません。
ホスト側は次のように Kernel をロードするものの increment に対してはenqueueTask しません(ap_start がないから)。
蛇足ながら、このソース cl:: という namespace でうまく OpenCL をラッピングしています。Khronos の提供する CL/cl2.h のようです。こちらの方がソースとしては見やすくなりますね。
RTL Kernel
RTL もインタフェースが合えば当然ながら組み込むことが出来ます。ap_clk や ap_rst_n や gmem や control といった名称がキーになります。生成される xo は実は zip なので、 I/F をチェックして xml をつけて zip にまとめただけということになります。
host/hbm_simple
HBM を使ったサンプル。カーネルのインタフェースは m_axi でgmem という bundle 名称。この gmem が HBM であると cfg で書くだけで後の転送は XDMA まかせ。簡単なものならこれで十分。バースト転送も struct をつかっているので出来るのでしょう(未確認)。
別のサンプルで hbm_large_buffers というのもあってこれは out_r がgmem2 になっている。確かにその方が速そう。
#pragma HLS INTERFACE m_axi port = in2 offset = slave bundle = gmem1
#pragma HLS INTERFACE m_axi port = out_r offset = slave bundle = gmem0
#pragma HLS INTERFACE s_axilite port = in2
#pragma HLS INTERFACE s_axilite port = out_r
#pragma HLS INTERFACE s_axilite port = size
#pragma HLS INTERFACE s_axilite port = return
OpenCL Kernel
もうあまり使わないかもしれません。.cl の拡張子のついた由緒正しいOpenCL のプログラムです。
一部分だけソースを引用します。あまりきれいじゃないですね。