FPGA で浮動小数点数を計算する。計算時のレイテンシが4のときにどういうことが起こるのか?を見ていく。
この記事は前回の続き
レイテンシ4
私が作った FPGA の浮動小数点数の加算器はレイテンシが4になった。赤く囲った場所が一連の処理になる。t=0 の時 a と b の入力がありt=3 のときに c の結果を得る。

パイプラインのデータの受け渡し
データの受け渡しに絞って一連の処理を見てみる。
この時、ステージ内で計算された中間結果は次のクロックで次のステージの入力として保存される。
結果として、各ステージには入力がレジスタとして必要とされる。
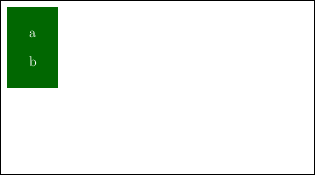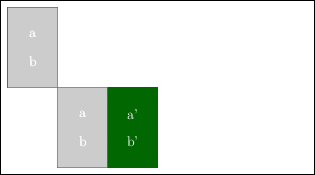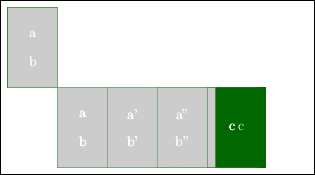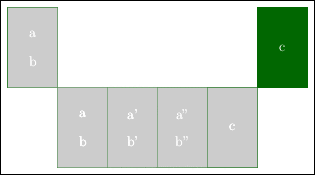
SIMD でいうデータプール
さて、翻って SIMD をもう一度考えてみよう。
ぼや〜んとした Data Pool からデータがやってきている。出力先もどこだかわからない。

具体的に検討するために Data Pool を CPU あるいは GPU のRegister であるとしよう。
乗算器の入力元は Register であり、出力先も Register ということになる。

入出力先が同じリソースを持つパイプライン
連続した演算することを考えるとどうしても入出力先が同じになってしまう。計算にはレイテンシがあるため、計算結果を利用した計算はそのレイテンシ分遅れて計算することになる。
a, b, c としていた変数をレジスタ番号の r1, r2, r3 として考え直してみよう。
下の図では r3 = r1 * r2 の計算を開始た後に、すぐ r3 を利用しようとしている。この場合、まだ r3 の結果は t=1 では得られていないので、データに依存関係があれば、r3 を使用した計算は間違った結果を生む。

ちゃんとした計算をしようとしたら途中に NOP はさみ、計算を遅らせる必要がある。
レイテンシが4のため、途中に3つの NOP が必要となる。折角あるアクセラレータである乗算器が 4 回に 1 回しか使用されない。
甚だ、効率が悪い。これを高速化のためになんとか詰め込みたい。

To Be Continue...